Bei welchen Krankenkasse sind in den Regelleistungen Behandlungen mit Homöopathie möglich? Die folgende Übersicht versucht die Frage für einige gesetzlichen Krankenkassen zu beantworten. Es sind nur die mitgliederstärksten Krankenkassen verzeichnet. Die Erhebung wurde im Mai 2021 durchgeführt und es besteht keine Garantie auf Vollständigkeit.
Das Ergebnis ist sehr unerfreulich, es sind eindeutig zu viele Krankenkassen die Homöopathische “Behandlungen” bezahlen. Am dreistesten ist sicherlich die HKK, welche es unter den Namen Naturarzneimittel in ihrem Katalog aufführt.
Wählt weise!
Krankenkassen die teilweise alternative Medizin anbieten:
- KKH
- Heilpraktikerbehandlung nur über Bonusprogramm
- Akkupunktur nur bei chronischem Leiden
- Ostheopathie
- IKK
- Pro Jahr maximal 150 Euro für Ostheopathie
- Debeka BKK
- Akkupunktur bei zertifizierten Ärzten
- Keine Behandlung bei Heilpraktikern
- Ostheopathie: maximal sechs Sitzungen pro Kalenderjahr, jedoch nicht mehr als 40 EUR je Sitzung
- AOK
- Akkupunktur (chronische Schmerzen, Vertragsarzt)
Krankenkassen die Homöopathie unterstützen:
- Barmer
- TK
- DAK
- HKK
- getarnt unter dem Deckmantel Naturarzneimittel
- HEK
- BKK24
- Heimatkrankenkasse
- Novitas BKK
- Knappschaft
- Landwirtschaftskrankenkasse
- BKK-Mobil
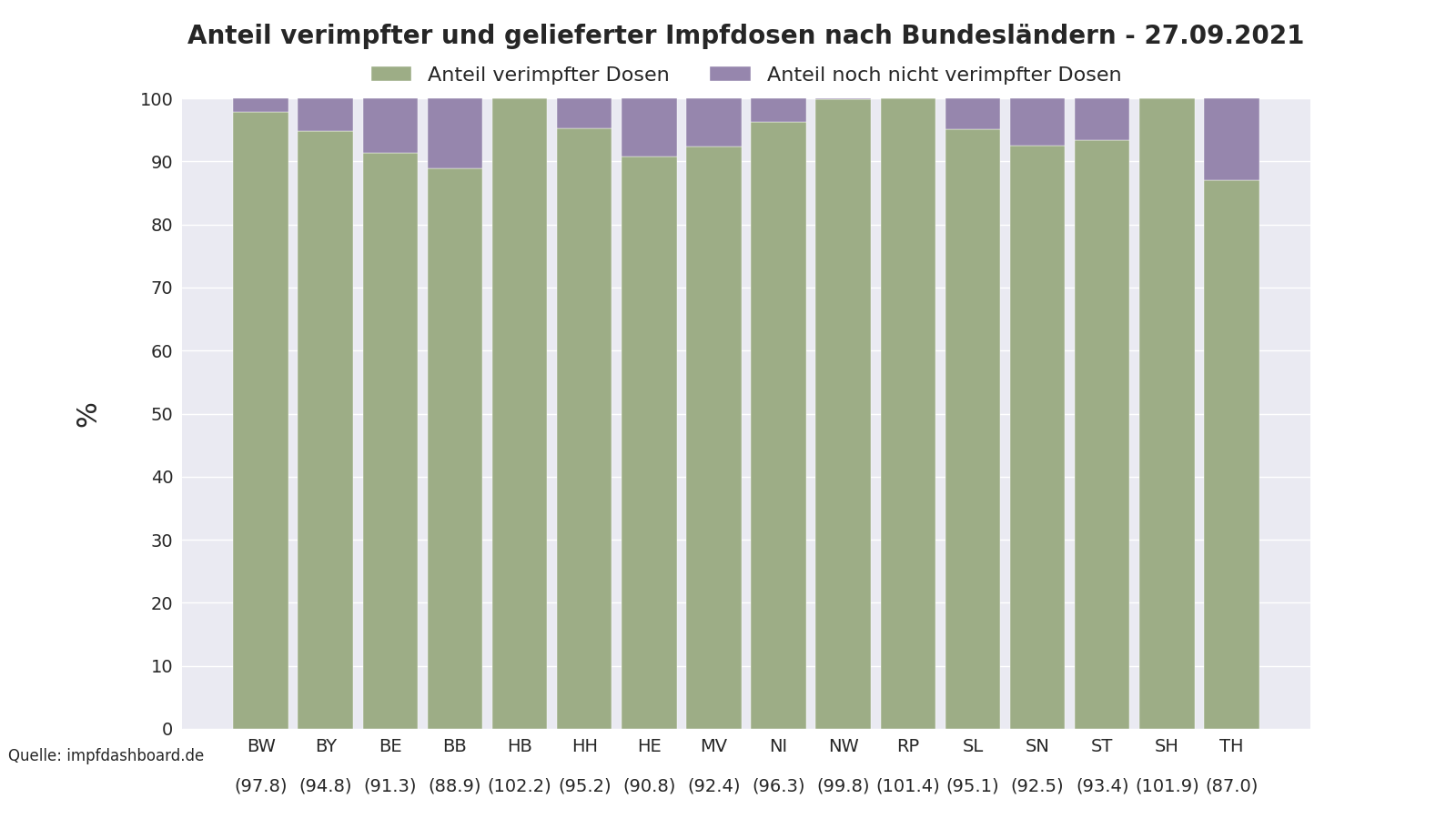
Das Impfdashboard des Bundesministeriums für Gesundheit bietet viele Informationen zum Impffortschritt. Jedoch fehlt ein Vergleich der Bundesländer und ihrer verimpften Dosen im Verhältnis zu den gelieferten Dosen.
Die folgende Grafik bietet diesen Vergleich und wird täglich aktualisiert. Als Quellen dienen die zur Verfügung gestellten Daten des Impfdashboards. Sie ist auch im Bereich covid19-plots hinterlegt.
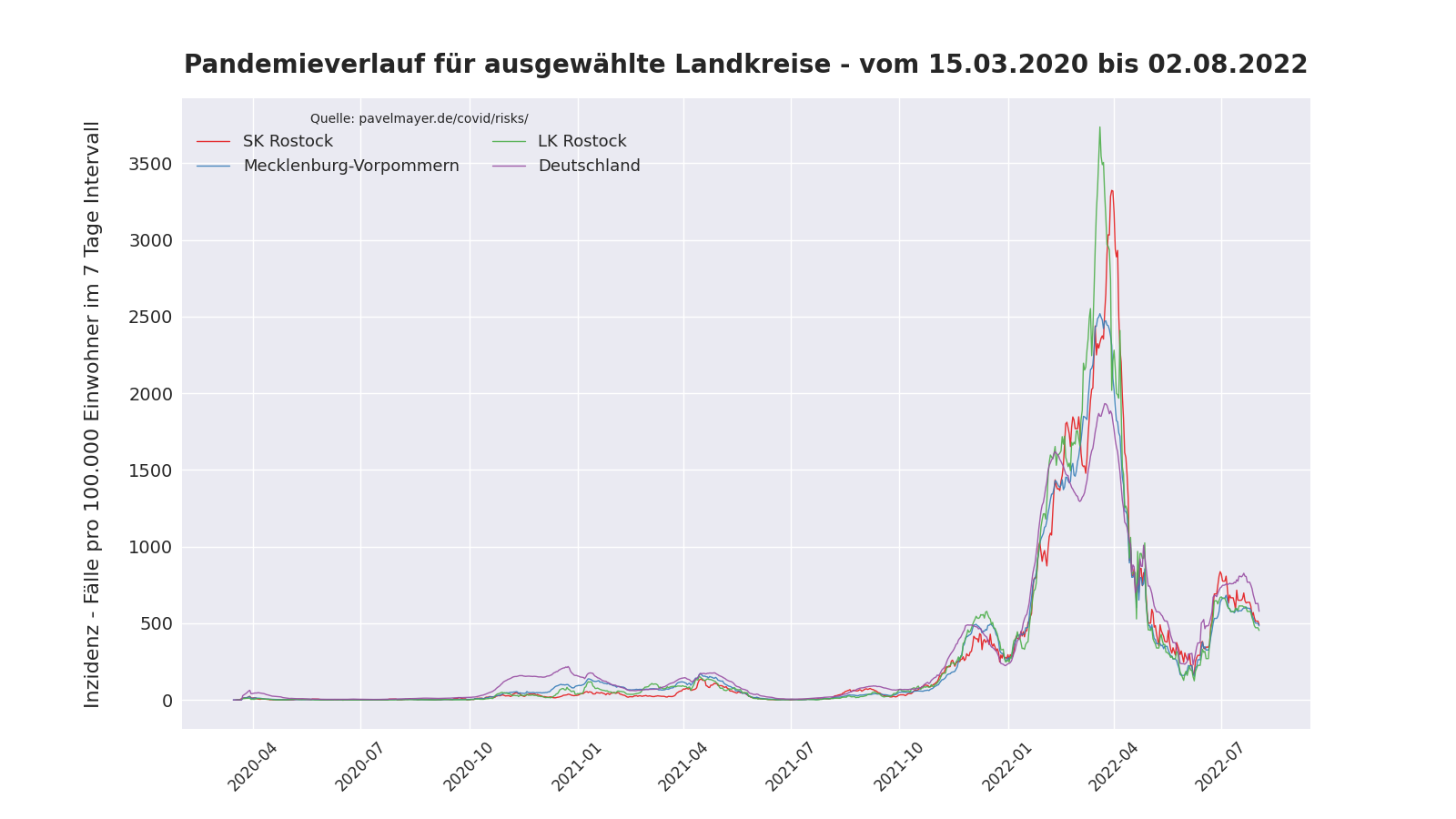
Im Bereich covid19-plot wurde eine neues Diagramm hinzugefügt. Es zeigt den bisherigen Verlauf der Pandemie anhand der Inzidenz (Fälle pro 100.000 Personen) für Rostock, Mecklenburg-Vorpommern und Deutschland.
Für ein zukünftiges Projekt würde ich gerne die Qualität von Kompressionsalgorithmen für das folgende Problem bewerten: Es sollen viele kleine Objekte mit pickle serialisiert und über ein Netzwerk übertragen werden. Die Objekte können sich in ihrer Größe unterscheiden, werden aber grundsätzlich nicht zu komplex. Auch ganze Warteschlangen, bestehend aus diesen Objekten sollen übertragen werden. Für die Vergleiche werden folgende Objekte zufällig generiert (als BNF notiert):
Objekt = id, timestamp, {value}, description
id = ? int64 ?
timestamp = ? int32 ?
value = float
description = {Character}
Character = ? printable ascii characters ?
Als Kompressionsalgorithmen kommen zlib, zstd, lz4 und lzo in Frage. bz2 und lzma reduzieren den benötigten Platzbedarf zwar am meisten, sind aber auch erheblich langsamer als der Rest. Die benötigte Zeit ist das ausschlaggebende Kriterium. Da mich das Verhalten im Zusammenspiel mit Python3 interessiert wurden die Vergleiche auch mit Python3 (3.9.1) durchgeführt. Dabei wurden folgende externe Module verwendet:
Die Module zlib, bz2 und lzma sind teil der Standardbibliothek.
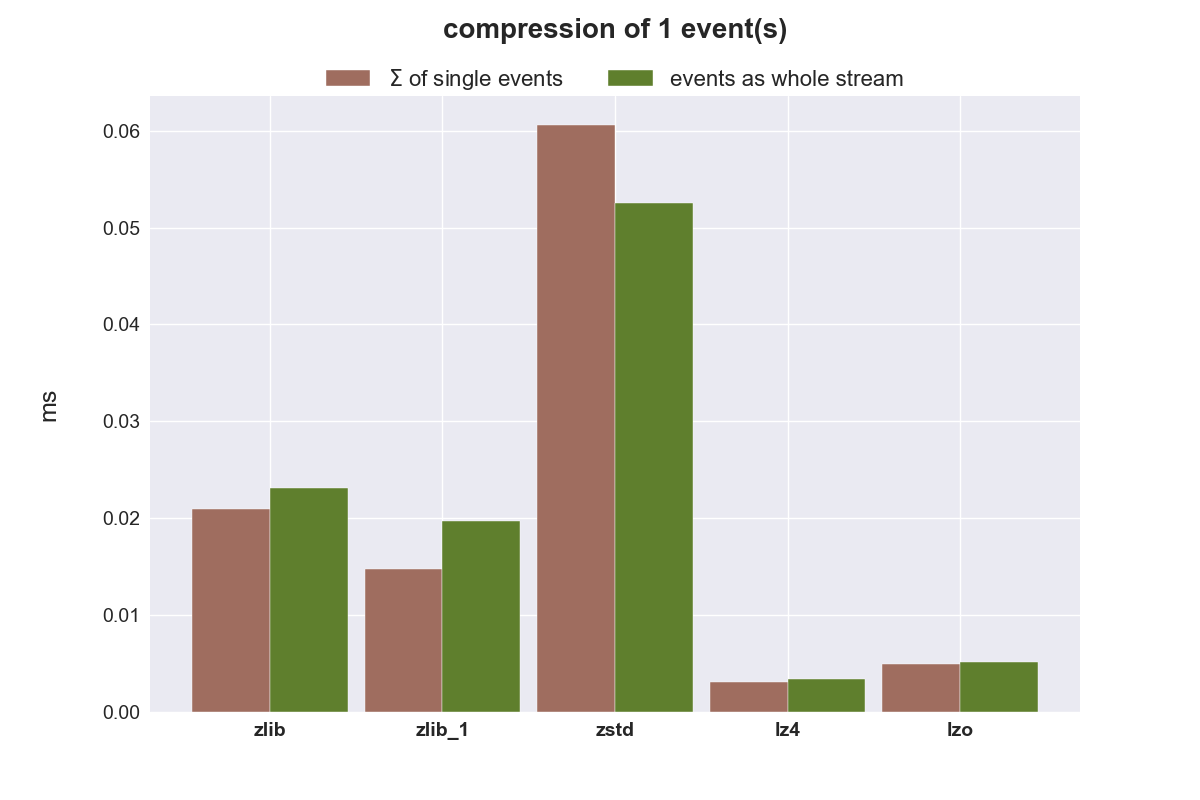
Kompression eines einzelnen Objektes
Die folgende Grafik zeigt die benötigte Zeit (Millisekunden), um ein Objekt einzeln und innerhalb einer Liste zu komprimieren.
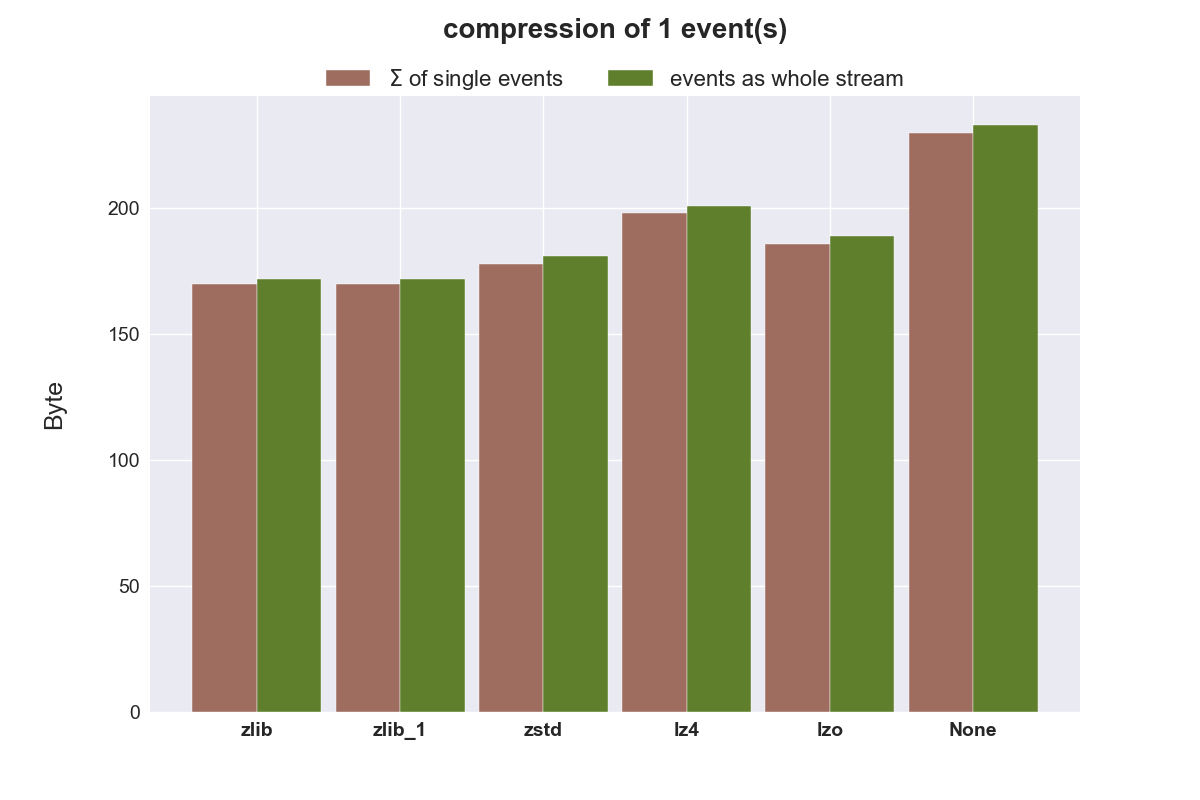
Hier wird die Größe in Byte nach der Kompression gezeigt. None ist die Größe der Quelldaten.
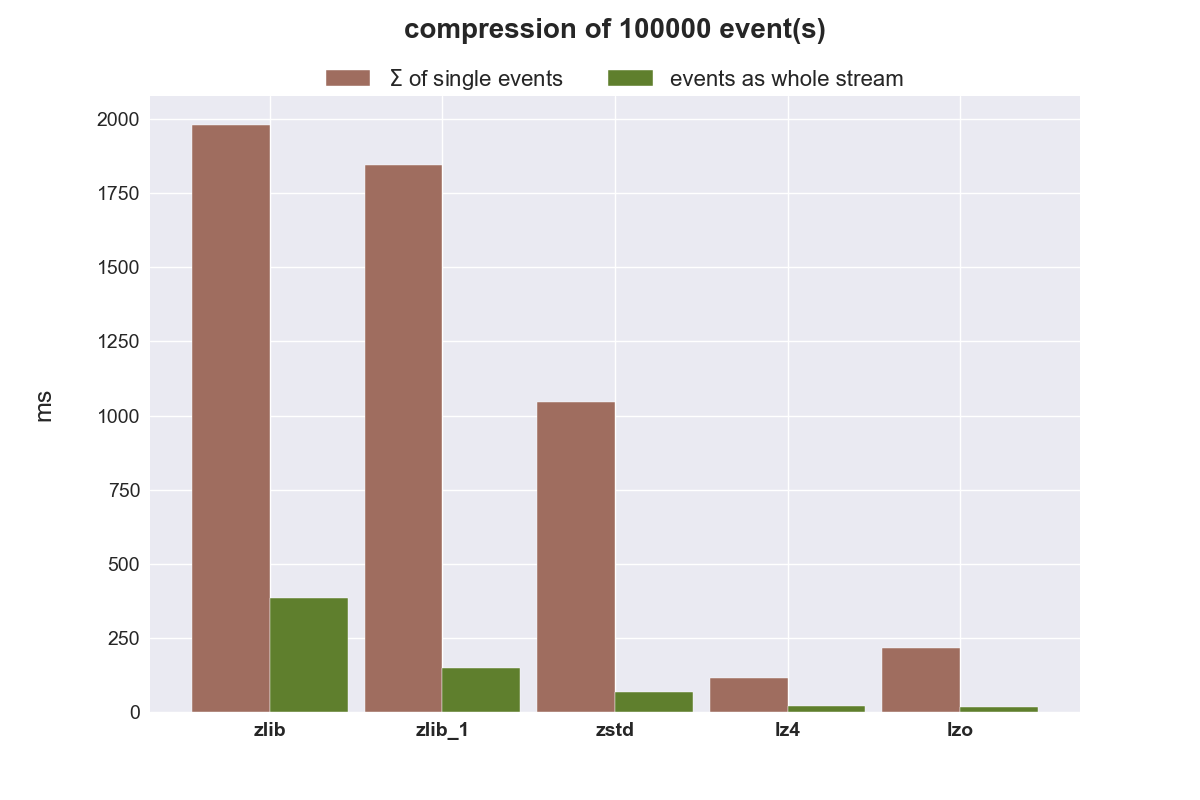
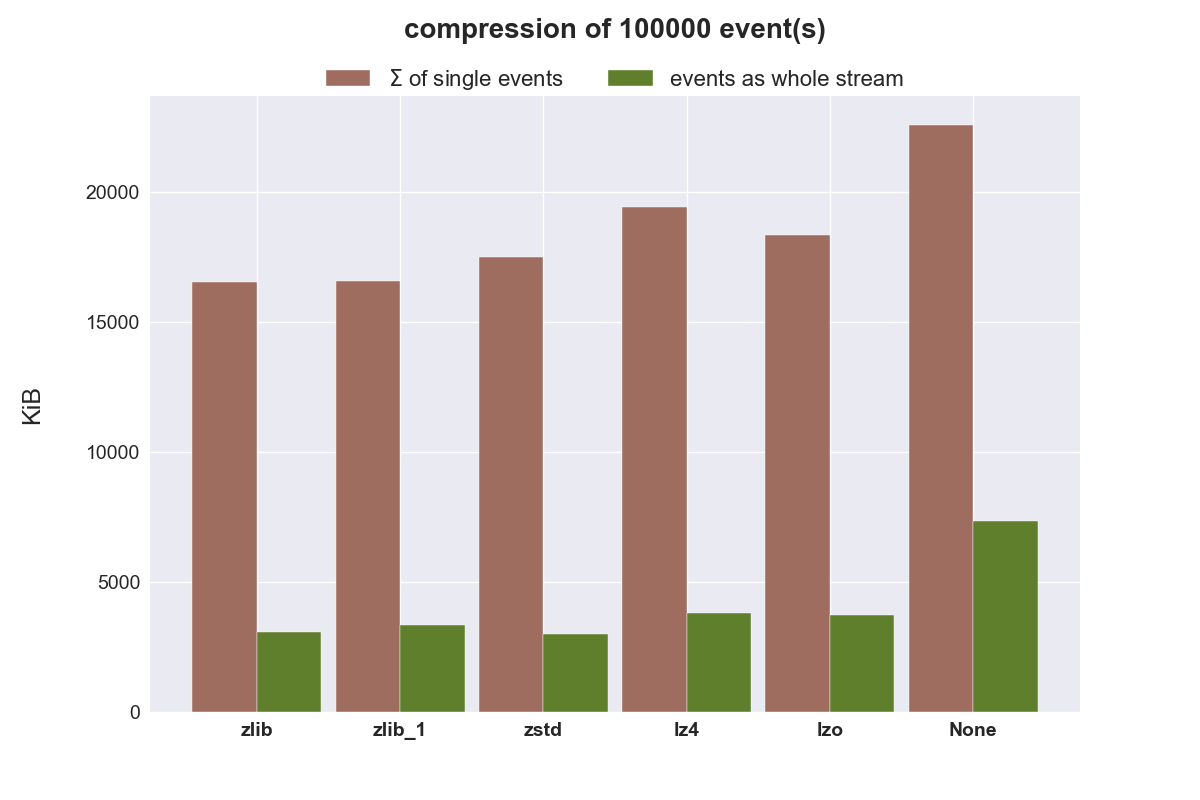
Kompression von 100.000 Objekten
Nachfolgende Plots zeigen die aufsummierte Zeit und Datenmenge, wenn 100.000 Objekte einzeln komprimiert werden und zusammen als liste.
Dekompression der Objekte
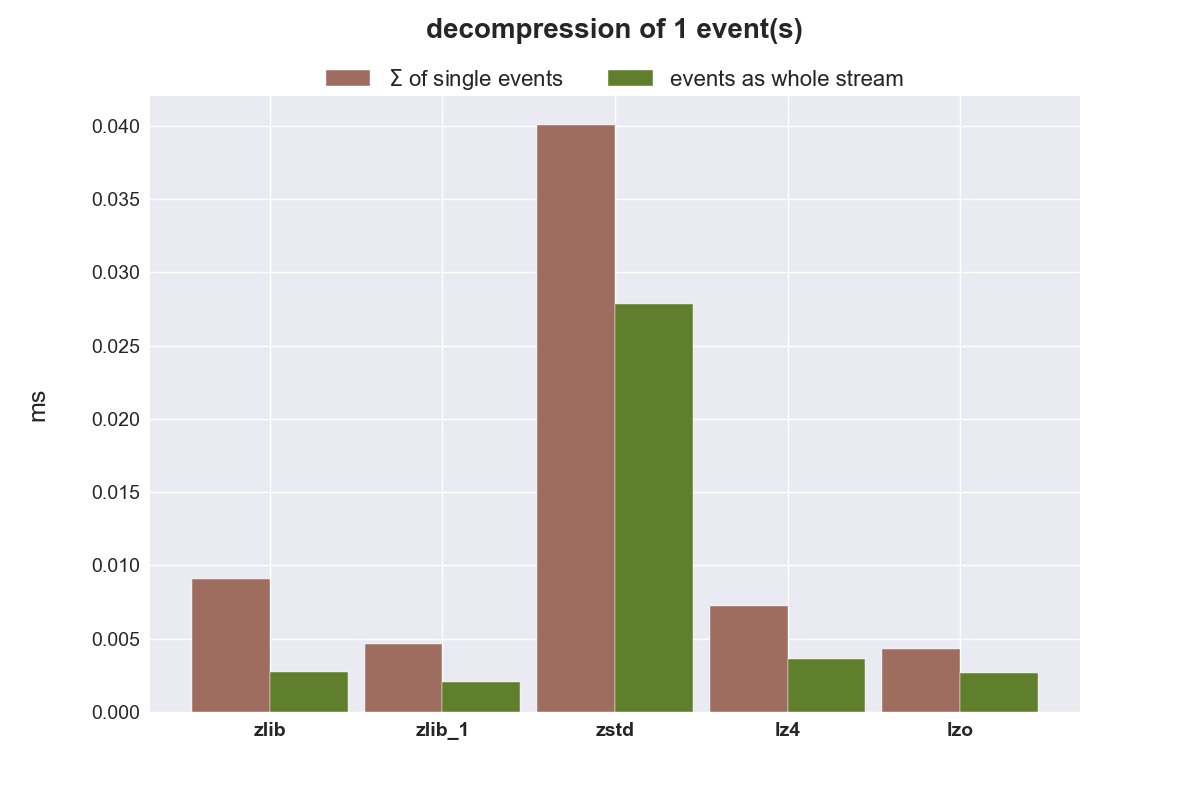
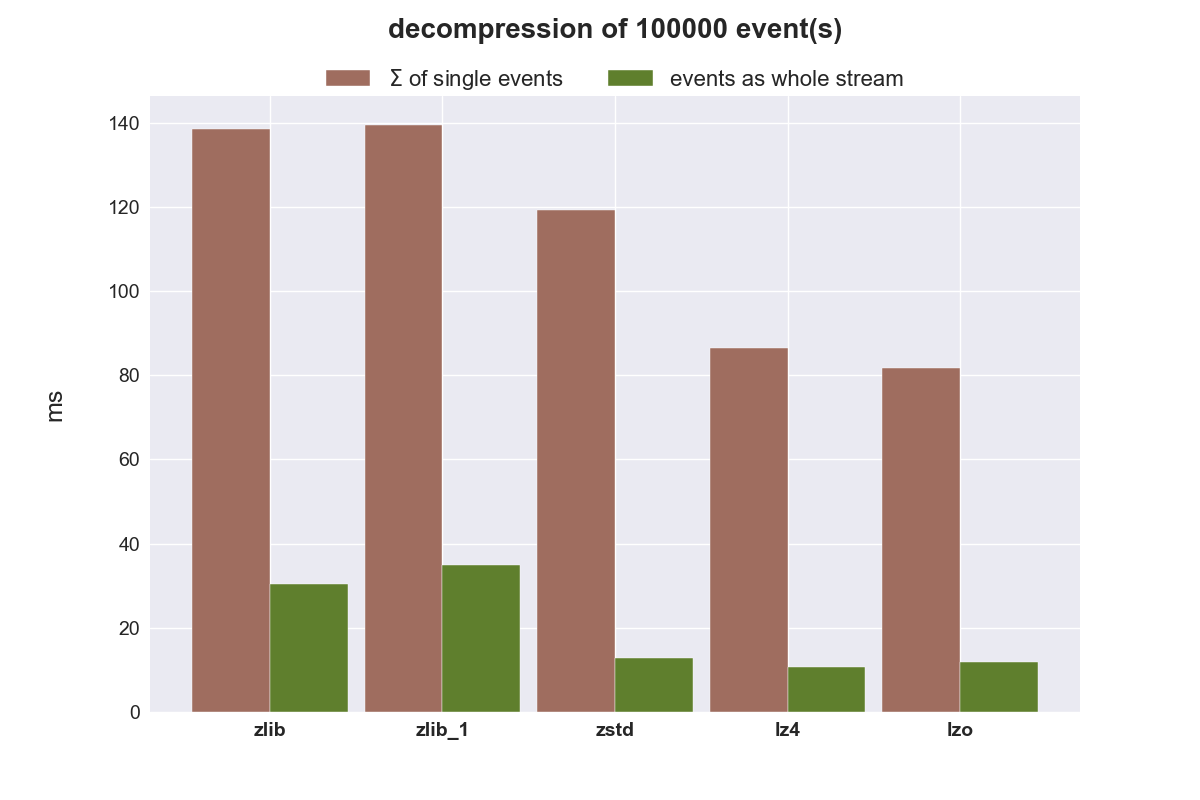
Zum Schluss wird noch die benötigte Zeit für die Dekompression der Daten verglichen.
Fazit
Pickle arbeitet sehr schnell und legt die serialisierten Daten effizient ab. Wenn 100K Objekte in einer Liste verpackt werden, benötigen diese nur 1/3 des Speicherplatzes, als wenn jedes Objekt einzeln serialisiert wird.
Einzelne Objekte (Events) zu komprimieren und sie im Anschluss zu übertragen scheint ineffizient zu sein, der eingesparte Speicherplatz für diese kleinen Objekte ist einfach zu gering. Bei größeren Objekten könnte eine Kompression wieder wieder sinnvoll sein. Man könnte größere Objekte soweit Komprimieren, dass sie in ein einzelnes TCP/UDP-Segment passen.
zlib ist einfach zu langsam, auch mit dem niedrigstem Kompressionslevel (zlib_1). zstd eignet sich überhaupt nicht um kleine Datenmengen zu komprimieren, schneidet aber bei größeren Datenmengen hervorragend ab. zstd reduziert den benötigten Speicherplatz am besten, benötigt zur Kompression aber mehr Zeit als lzo und lz4, ist jedoch bei der Dekompression nur minimal langsamer als diese beiden sehr schnellen Algorithmen. zstd wäre damit der beste Kandidat um komplette Warteschlangen zu komprimiert zu übertragen.
Soll eine Kompression von einzelnen Events erfolgen, ist lz4 der favorisierte Kandidat. Er komprimiert und dekomprimiert einfach am schnellsten.
Eine kurze Kritik über die automatisch Auschecken-Funktion der LUCA-App und warum diese unter Android derzeit nicht funktionieren kann, sowie die Konsequenzen die daraus für Nutzer der Luca-App und Betreiber entstehen können.
Update
[26.03.2021] Seit heute ist im Google-Playstore die Berechtigung für den Standortzugriff ausgewiesen (Version 1.4.12). Wenn man die App allerdings installiert, existiert diese Berechtigung nicht. Damit ist die App immernoch nicht in der Lage einen automatischen Checkout vorzunehmen.
[21.04.2021] Seit dem 26.03.2021 Hat sich am Zustand der App nichts geändert.
LUCA-App in Mecklenburg-Vorpommern
Mecklenburg-Vorpommern ist das erste Bundesland das eine Betreiberlizenz für die LUCA-App erworben hat. Es wird offensiv mit der Nutzung der App geworben. Der Preis dieser Lizenz ist unbekannt.
Allgemeine Kritik an der Luca-App
Ich beziehe mich im folgenden auf die Android-Version der LUCA-App.
Ich befürworte ausdrücklich die Nutzung von IT-Lösungen zum Zweck der Kontaktnachverfolgung. Die Corona-Warn-App ist ein gutes Beispiel für eine datenschutzfreundliche und offene Lösung, der Entwicklungsprozess ist komplett transparent und auch das zugrundeliegende Exposure Notification Framework von Google ist mittlerweile im Quellcode verfügbar. Zudem gibt es einen Google-freien Nachbau des Frameworks vom MicroG-Projekt und auch einen Fork der originalen Corona-Warn-App namens Corona Contact Tracing Germany , die das MicroG-Exposure-Framework verwendet. Der einzige Kritikpunkt an der Corona-Warn-App könnten die hohen Entwicklungskosten sein. Wie viel die Luca-Lizenzen in Summe kosten ist aber auch noch unklar. Aus Datenschutzgründen hat man sich im November 2020 entschieden, keine Kontaktnachverfolgung im Sinne der LUCA-App in die Corona-Warn-App zu integrieren, um nicht das Vertrauen in die App zu verspielen. Stattdessen nehmen wir einfach eine nicht überprüfte Software von einem Berliner Start-up?
Genau die oben beschriebenen Vorteile, die auch das Vertrauen in die Luca-App stärken würden, da unabhängige Experte sich den Code anschauen könnten und Verbesserungsvorschläge einreichen können, fehlen in der LUCA-App komplett. Stattdessen setzt man offensichtlich auf eine strikt proprietäre Lösung, die nicht einmal einen Audit durch externe Firmen erfahren hat. Zudem werden Lizenzverhandlungen hinter verschlossenen Türen durchgeführt.
LUCA-App verwendet Geofencing - oder doch nicht?
Seit Montag, dem 01.03.2021, ist es Frisören in MV wieder erlaubt zu öffnen. Natürlich mit der Bitte die LUCA-App zu verwenden. Eine Frisörmeisterin aus Rostock hat im Lokalradio von ihren Erfahrungen mit der LUCA-App berichtet. Sinngemäß wurde die Möglichkeit gelobt im Betreiber-Modus einen Radius zu erstellen, aus dem man automatisch ausgecheckt wird: Ist ein Nutzer mit der LUCA-App im Frisörsalon eingecheckt und verlässt den voreingestellten Radius, wird er automatisch ausgecheckt. Für die Frisörmeisterin eine hervorragende Funktion, Kunden müssen sich somit nicht manuell auschecken.
Wie funktioniert das automatische Auschecken?
Ganz einfach: Die Position des Smartphones muss zu jedem Zeitpunkt bekannt sein. Kurz gesagt, die LUCA-App braucht Zugriff auf die Ortungsfunktionen des Smartphones. Ortungen mit metergenauer Auflösung könnte folgendermaßen durchgeführt werden:
- Verwendung des GPS/GLONASS/GALILEO - Empfängers des Smartphones
- sehr genau
- nur außerhalb von Gebäuden
- Ungenaue Ortung mittels bekannten Netzwerken (WiFi, Cell-Based)
- Externe Datenbanken müssten angefragt werden (Google-Services)
- Genauigkeit hängt von der Datenqualität der entsprechenden Region an
- Ortung mittels Funkfeuer (zum Beispiel mittels Bluetooth-Low-Energie-Beacons)
- Stark begrenzte Reichweite (wenige Meter)
- Ungenau
- Smartphone des Betreibers oder spezielle BLE-Sender müsste BLE-Beacons aussenden
Alle drei Verfahren benötigen aber Zugriff auf die Standortdaten des Android-Smartphones. Das automatische auschecken auf Basis von Standortdaten scheint optional zu sein, das wird aber im Betreiber-Modus, während der Eintragung eines Radius nicht erwähnt.
Zusätzlich existiert noch die Möglichkeit eine sehr grobe Standortbestimmung mittels IP-Adressen vorzunehmen. Dieses Verfahren ist aber für die metergenaue Bestimmung unbrauchbar und auch nicht zuverlässig. Je nach Qualität der Daten kann man lediglich die Region (z.B. Stadt) bestimmen in der man sich aufhält. Diese Bestimmung benötigt keine gesonderten Berechtigungen auf dem Smartphone.
Nur die FAQ auf der Homepage bietet eine kurze Bemerkung, aber nicht wie Geofencing in der LUCA-App umgesetzt ist.

Automatisches Auschecken kann zur Zeit unter Android nicht funktionieren.
Wie schon erwähnt, müsste die LUCA-App Zugriff auf die Standortdaten haben um überhaupt das metergenaue automatische Auschecken zu ermöglichen. Derzeit wird diese Funktion durch die Android-App (Version 1.4.9) überhaupt nicht angeboten. Die Berechtigungen der App im Play-Store gibt eindeutig Auskunft darüber:
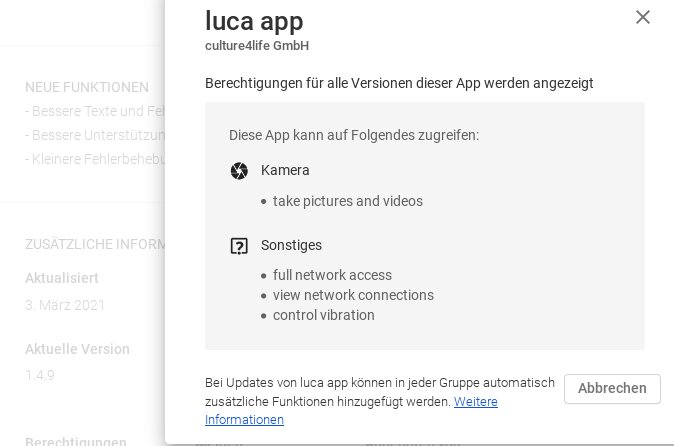
Auch nach der Installation der App existiert keine Möglichkeit der Standortabfrage:
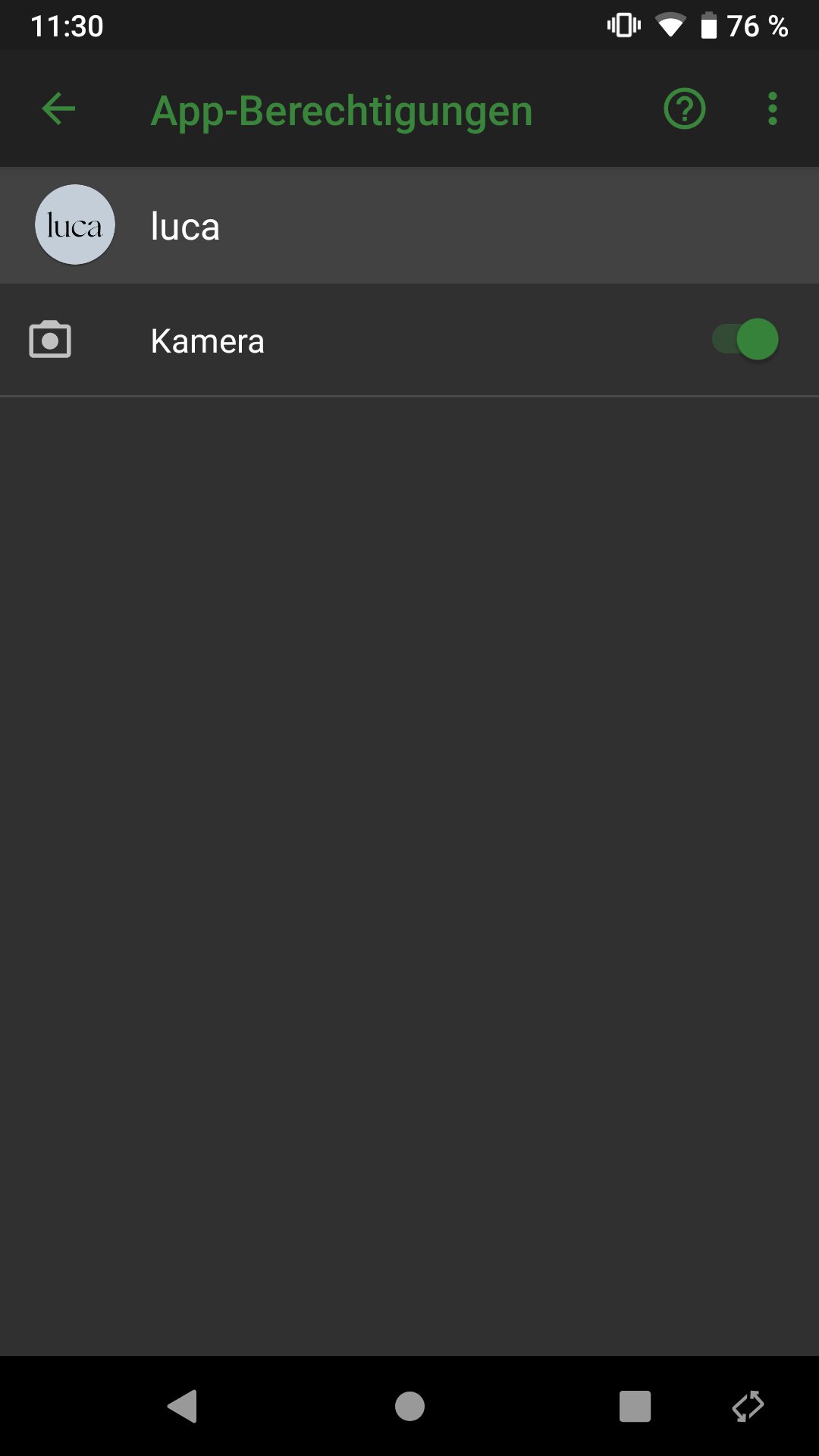
Wie soll metergenaues auschecken unter Android so möglich sein? Gar nicht!
Die iOS-Version der App (Version 1.3.1) scheint die Möglichkeit der Standortabfrage zu bieten.
Abseits großer datenschutzspezifischer Bedenken, dass ein Unternehmen somit in der Lage wäre Bewegungsdaten tausender Menschen zu erfassen, kann diese Funktion einfach nicht benutzt werden.
Konsequenzen
Das automatische Auschecken wird im Betreiber-Modus der LUCA-Web-App zentral beworben, kann aber nicht funktionieren. Wenn sich technisch nicht versierte Betreiber und Gäste auf diese Funktion verlassen, ist das in meinen Augen ein schwerer Fehler. Es kann sogar dazu führen das eigentlich unbeteiligte Betreiber in Quarantäne müssen und so eventuell ihren Geschäftsbetrieb einstellen oder einschränken müssen, da sich Gäste eigentlich woanders infiziert haben, aber nicht ausgecheckt waren. Das kann natürlich auch Gäste treffen die sich auf das automatische Auschecken verlassen und später eine Quarantäne Aufforderung bekommen, obwohl sie schon lange nicht mehr vor Ort waren.
Forderung an die Entwickler der LUCA-App
Rücknahme der Geofencing-Funktionen aus Datenschutzgründen und aufgrund unvollständiger Unterstützung des eigenen Softwarestacks.
Klare und detaillierte Beschreibung der Architektur.
Audit des gesamten LUCA-Softwarestacks durch mindestens zwei unabhängige Unternehmen.
Forderung an Regierungen und Städte die eine LUCA-Lizenz erworben haben
Veröffentlichung von Preislisten oder gezahlten Preise für Lizenzen.
Druck auf die Entwickler erhöhen, den Code (Apps + Server) zu publizieren (public money public code!).
- Zum Beispiel kauf des Start-up und Umwandlung in Bundes-/Landeseigene Unternehmung
Impfmonitoring
Alle Grafiken werden stündlich aktualisiert, sofern neue Daten zur verfügung stehen.
Der Quellcode steht auf github zur Verfügung.
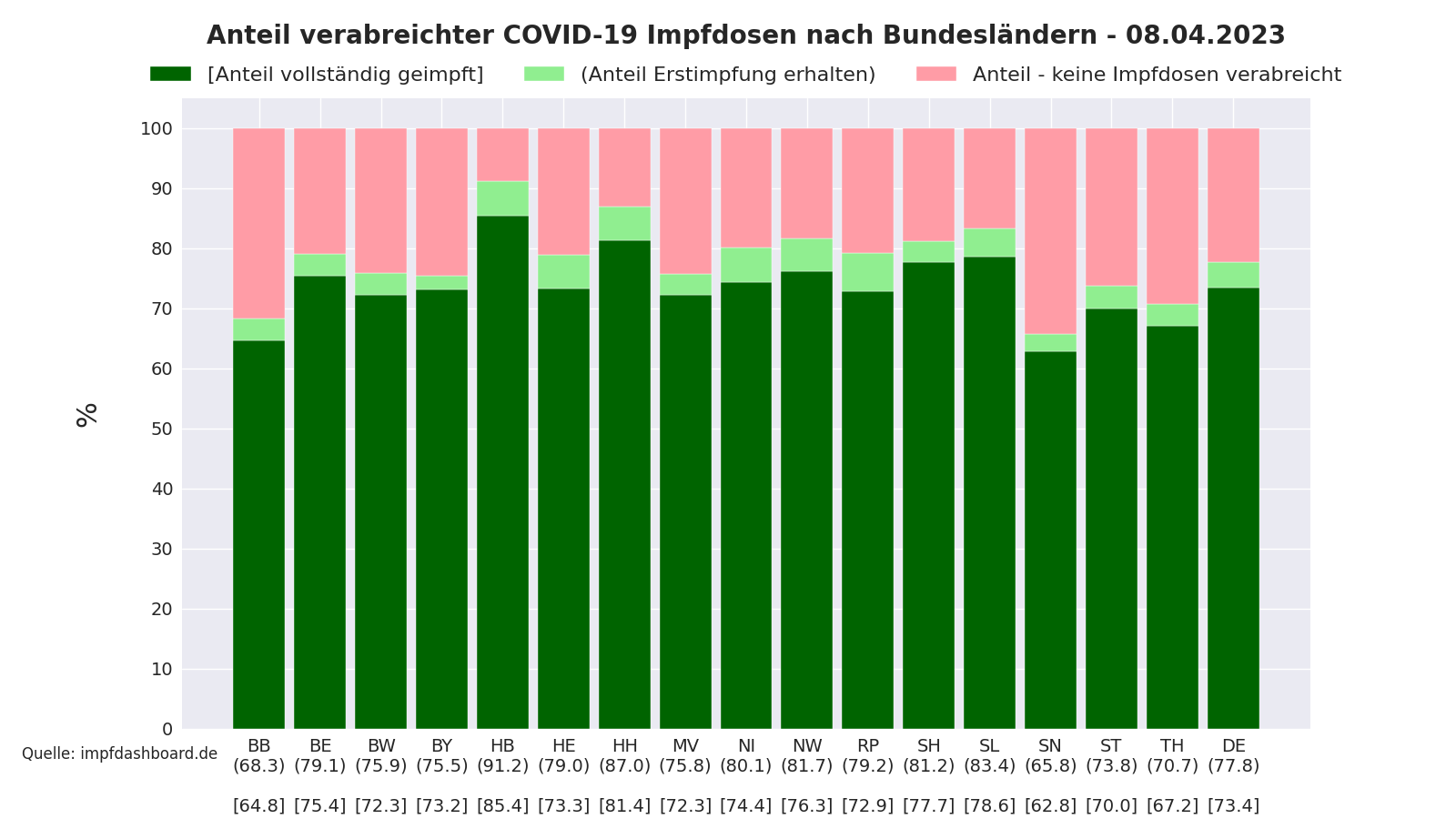
Folgender Plot zeigt den nach Bundesländern aufgeschlüsselten Impffortschritt an. Als Quelle dienen Daten vom Impfdashboard.
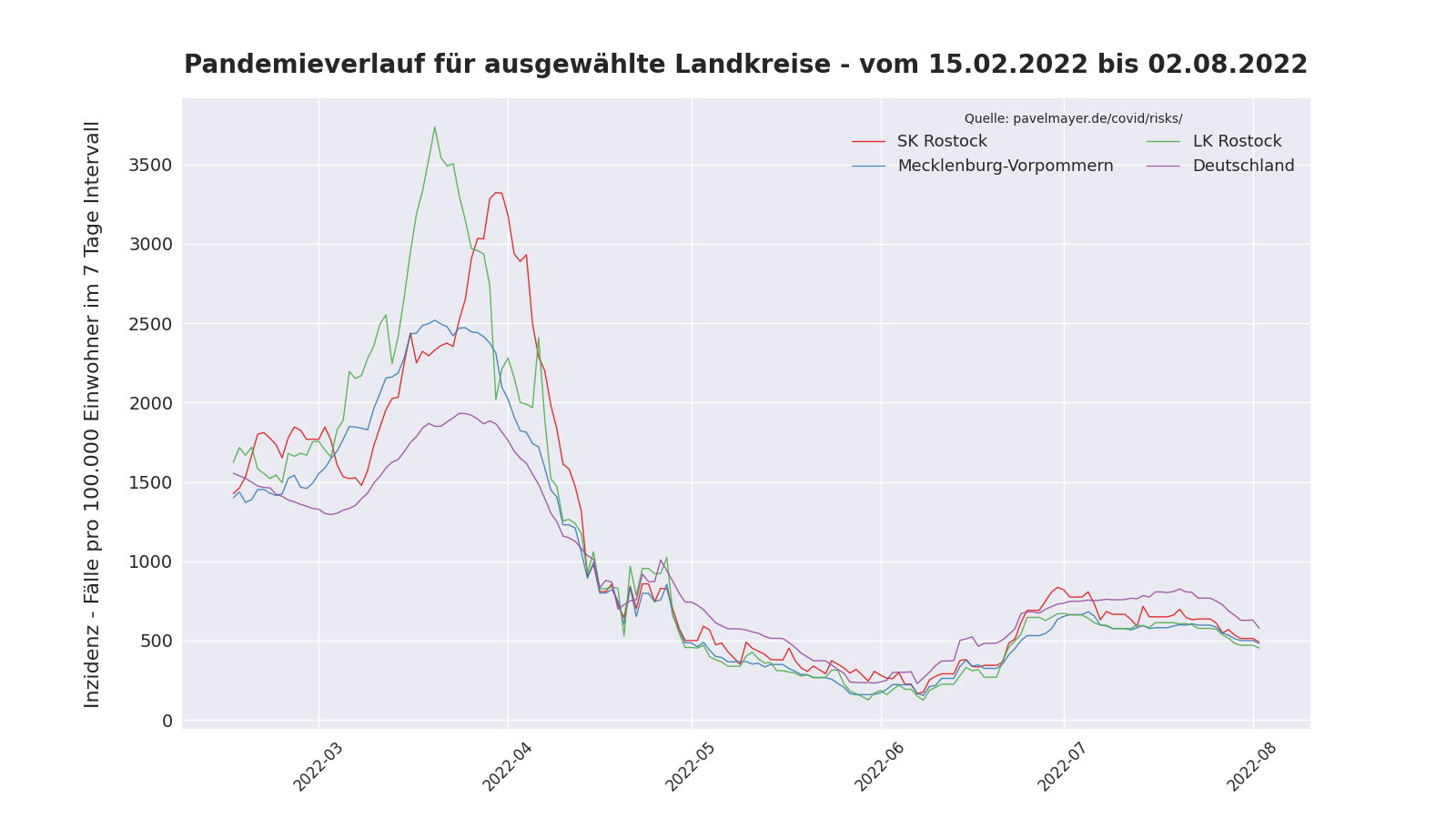
Pandemieverlauf in Rostock
Folgender Plot basiert auf den Daten aus Pavel Meyers Covid-Risiko-Tabelle. Das erzeugende Skript kann beliebige Landkreise, Städte, oder Länder plotten und ist auf github veröffentlicht.
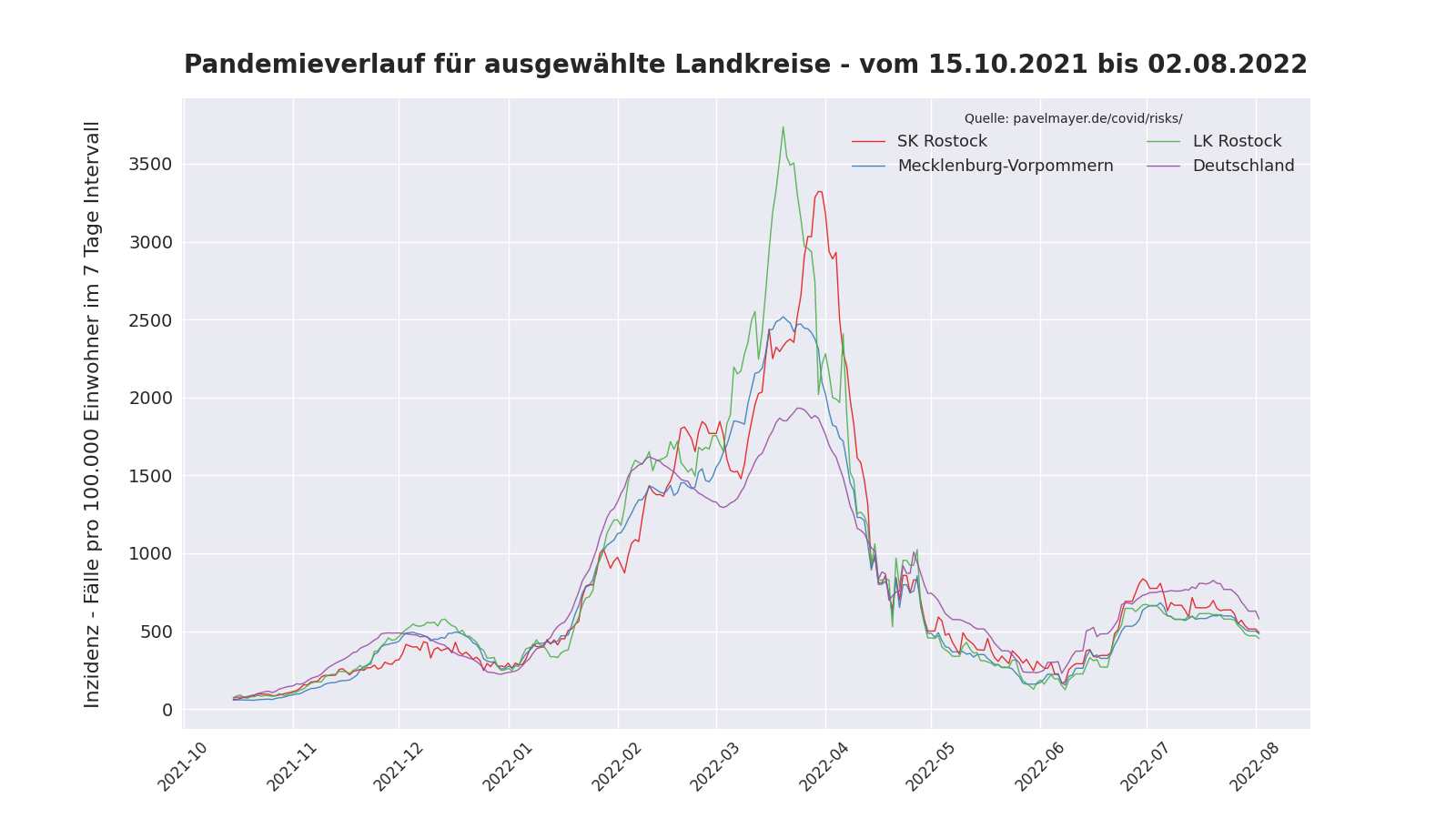
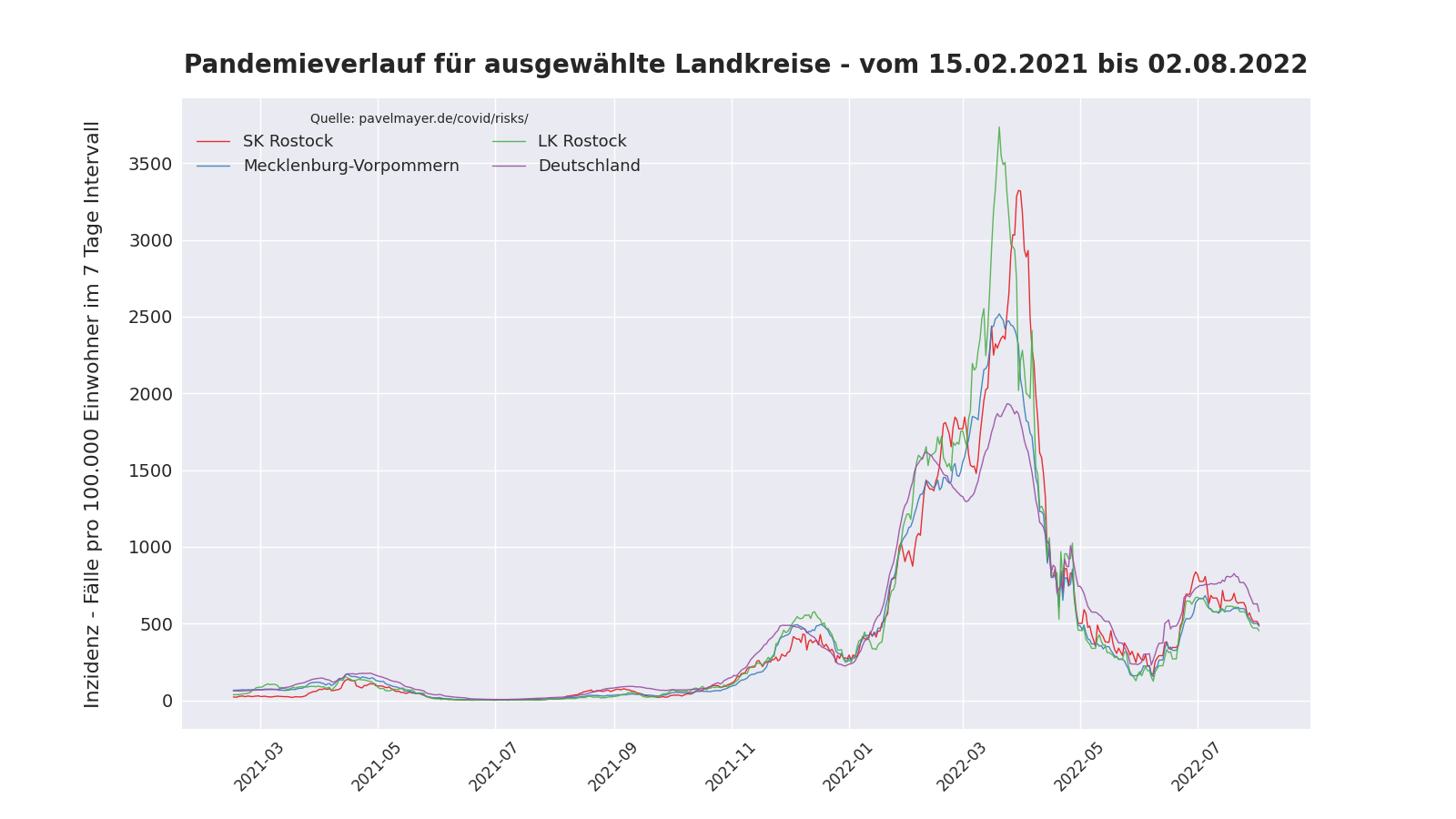
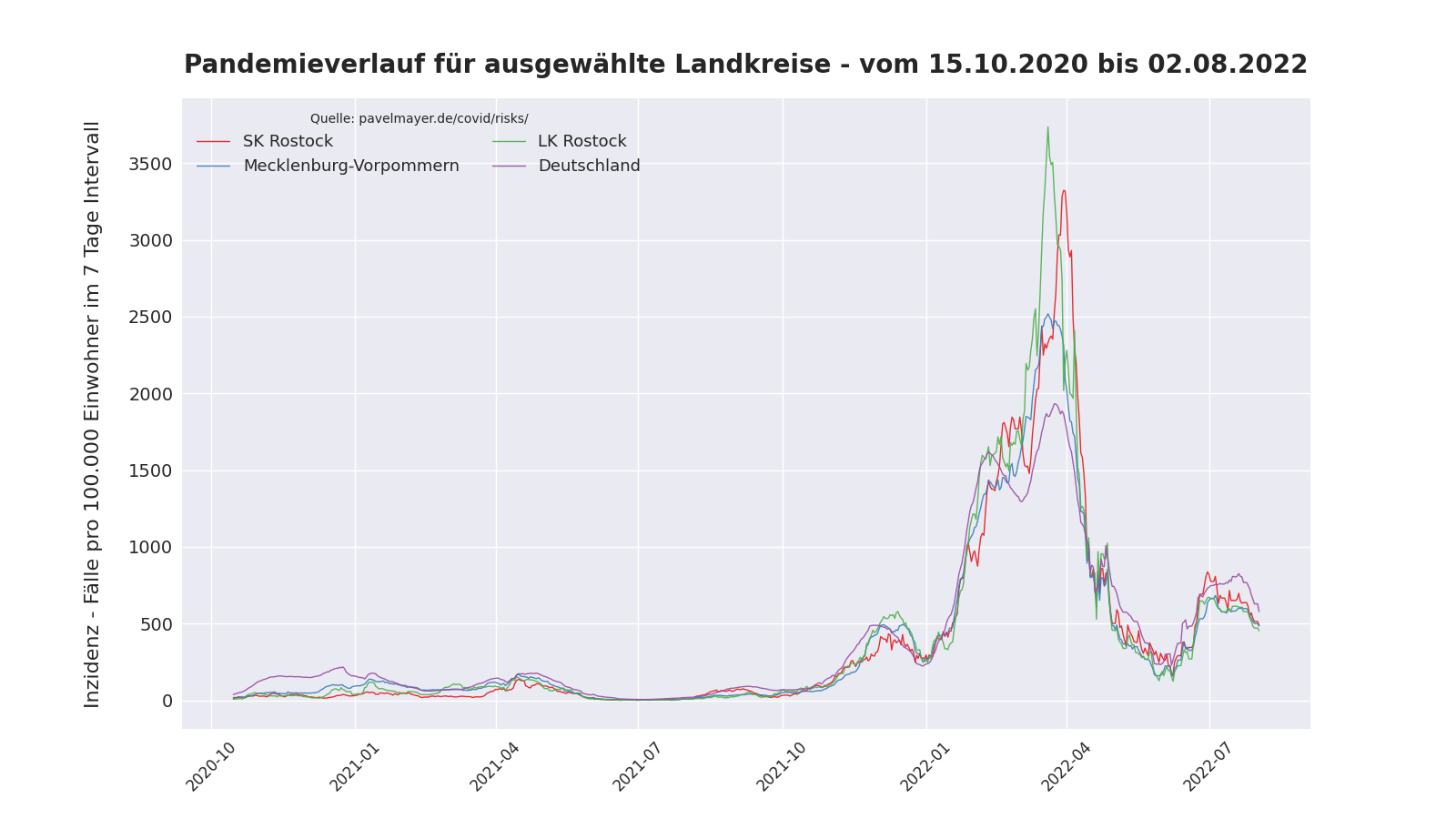
Updates
[11.06.2022] Neue Plots für die Zeiträume vom 15.10.2021 und 15.02.2022
[06.04.2021] Plot zum Verhältnis von gelieferten zu verimpften Dosen hinzugefügt.
[16.03.2021] Plot zum Pandemieverlauf hinzugefügt.
[11.02.2021] Es wird nach Erst- und Zweitimpfung unterschieden.
[19.01.2021] Umstrukturierung der RKI-Tabelle, inkompatibel zur vorherigen Version Es existiert jetzt eine Aufschlüsselung nach Impfpräparaten.
[04.01.2021] Das RKI stellt seit heute auch die Impfquote pro 1000 Einwohnern und die Gesamtanzahl der Impfungen der letzten Tage in ihrer Excel-Tabelle bereit.
Alternativen:
Dieser Artikel beschreibt die Konfiguration eines Wireguard - VPN-Servers auf debian 9 (stretch,stable). Sämtlicher IPv4- als auch IPv6-Verkehr eines Roadwarriors soll durch Wireguard getunnelt werden. Als Server kommt ein Hetzner-Cloud-server CX11 zum Einsatz. Für 2,96€ im Monat bekommt man genügend Leistung, eine fixe IPv4-Adresse und ein IPv6-Netz (/64) zugewiesen.
Wireguard ist eine moderne VPN-Lösung mit einer sehr schmalen Codebasis. Wireguard implementiert nur wenige, dafür aber aktuelle Verschlüsselungsverfahren und läuft, anders als zum Beispiel OpenVPN, im Kontext des Kernels. Eine detaillierte Beschreibung des Protokolls und eine Übersicht über die verwendeten kryptografischen Verfahren kann man im Wireguard-whitepaper nachlesen. In den nächsten Monaten (stand März 2019) soll Wireguard Aufnahme in den Linux-Kernel finden. Für debian 10 testing und unstable/sid stehen aktuelle Pakete in den debian-repositories bereit. Die Installation auf allen gängigen Linux-Distributionen und BSD-Systemen ist auf der Wireguard-Homepage beschrieben. Als Transportprotokoll setzt Wireguard ausschließlich auf UDP, möchte man stattdessen TCP einsetzen (einziger Grund wäre eine Blockierung von UDP), muss man Wireguard zum Beispiel über WebSockets tunneln.
Das Szenario
- Sämtlicher Verkehr soll über einen Tunnel geroutet werden.
- Die DNS-Auflösung und das Caching soll vom VPN-Server übernommen werden.
- Die Konfiguration auf dem VPN-Server soll persistent sein.
- Die Clientkonfiguration soll per QR-Code auf Apple-IOS/Android übertragen werden.
Installation
Da Wireguard ein Kernelmodul benötigt, muss das System zu dessen Übersetzung vorbereitet werden:
sudo apt-get install linux-headers-$(uname -r) build-essential
Für debian 9 stretch/stable existieren noch keine Pakete im offiziellen repository, daher muss das unstable-repository auf dem System verfügbar gemacht werden. Bei debian 10 kann dieser Schritt übersprungen werden. Dabei werden alle Pakete aus unstable jedoch so niedrig priorisiert, dass alle Pakete aus stable bei Updates den Vorzug erhalten, außer explizit installierten Paketen aus unstable:
$ sudo echo "deb http://deb.debian.org/debian/ unstable main" > /etc/apt/sources.list.d/unstable.list
$ sudo printf 'Package: *\nPin: release a=unstable\nPin-Priority: 90\n' > /etc/apt/preferences.d/limit-unstable
Im Anschluss wird Wireguard installiert und das Kernelmodul wird automatisch übersetzt und geladen:
$ sudo apt update && apt install wireguard
Ob das Kernelmodul geladen ist, lässt sich leicht überprüfen:
$ sudo lsmod | grep wireguard
Routing aktivieren
Damit der VPN-Server IPv4 und IPv6 Pakete weiterleitet muss diese Funktionalität dem Kernel mitgeteilt werden:
$ sysctl net.ipv4.ip_forward=1
$ sysctl net.ipv6.conf.all.forwarding=1
Um diese Einstellungen auch nach einem Neustart zu setzen, sind folgende Zeilen zur Datei /etc/sysctl.d/99-sysctl.conf zu ergänzen:
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
Erstellen der Schlüssel
Wireguard basiert auf dem Konzept des Crypto-Routing. Jeder Kommunikationsteilnehmer an einem VPN besitzt ein asymmetrisches Schlüsselpaar, der jeweilige öffentliche Schlüssel wird demjenigen Kommunikationspartner mitgeteilt, der über den Kommunikationskanal kommunizieren darf. Die Schlüssel sind sehr kurze base64-kodierte ECDH-Schlüssel. Die Schlüssel können auf jedem System, auf auf dem Wireguard verfügbar ist, generiert werden.
Schlüsselpaar für den VPN-Server:
$ wg genkey > vpn-server.seckey
$ wg pubkey < vpn-server.seckey > vpn-server.pubkey
Schlüsselpaar für einen weiteren Kommunikationsteilnehmer:
$ wg genkey > mobile.seckey
$ wg pubkey < mobile.seckey > mobile.pubkey
Optional ist die Generierung eines weiteren pre shared keys um eine weitere Schicht symmetrischer Verschlüsselung hinzuzufügen. Gründe hierfür werden in Abschnitt 5.2 des Wireguard-Whitepapers erläutert.
$ wg genpsk > vpn.psk
Wireguard-Konfiguration des VPN-Servers
Es existieren zwei Möglichkeiten Wireguard zu betreiben, man kann mithilfe von wg einen Tunnel
etablieren und Kommunikationspartner (peers) hinzufügen. Alternativ dazu hat man die Möglichkeit eine Konfigurationsdatei zu erstellen,
welche später von wg-quick eingelesen wird. Die zweite Möglichkeit hat den Vorteil, dass sich wg-quick auch gleich um die Erstellung
und Konfiguration der Wireguard-Netzwerkschnittstelle (im Beispiel: wg0) kümmert. Zudem bringt das Debian-Paket auch gleich ein
Systemd-Interface-Template mit, was ein Start des VPNs erleichtert und keine zusätzlichen Systemd-Kenntnisse erfordert.
Bevor die Konfiguration von Wireguard erfolgen kann, noch einige Worte zur IP-Adresskonfiguration von Hetzner. IPv4-Adressen
werden durch Hetzner per DHCP vergeben, sind aber persistent. IPv6 Adressen werden stattdessen statisch konfiguriert, Hetzner
verwendet dazu auf ihren debian Cloud-Servern die debian networking-scripte. Die IP-Adresskonfiguration findet sich unter:
/etc/network/interfaces.d/50-cloud-init.cfg.
Exemplarisch sind folgende Adressen auf dem Interface eth0 konfiguriert:
IPv4: 203.0.113.1/32
IPv6: 2001:db8:ffff:ffff::1/64
Da Wireguard über das virtuelle Tunnelinterface wg0 kommuniziert, müssen, jeweils für IPv4 und IPv6, interne Tunnel-Netze und Adressen
vergeben werden. Für IPv4 wählt man ein privates Netz gemäß RFC1918, in diesem Beispiel verwenden wir 172.16.100.0/24. Dem VPN-Server
wird später die erste Adresse aus diesem Bereich zugewiesen.
Die Adressen aus diesem privaten IPv4-Bereich müssen später noch einer Adressumsetzung auf die öffentliche Adresse 203.0.113.1 unterzogen werden.
Bei IPv6 hingegen reicht es aus das öffentliche Netz 2001:db8:ffff:ffff::/64 zu segmentieren. Zum Beispiel kann man das Netz in
256 Subnetze unterteilen: 2001:db8:ffff:ffff::/72. Die IPv6-Adresse auf eth0 ändert sich dadurch nicht, lediglich die Netzgröße.
Daher muss diese in der Datei /etc/network/interfaces.d/50-cloud-init.cfg angepasst werden:
#address 2001:db8:ffff:ffff::1/64
address 2001:db8:ffff:ffff::1/72
Im Anschluss muss die Konfiguration neu eingelesen werden:
$ sudo systemctl restart networking.service
Das zweite Netz aus dem IPv6-Bereich (2001:db8:ffff:ffff:100:/72) wird für die internen Tunneladressen verwendet.
Die Konfigurationsdatei von Wireguard muss nach dem Wireguard-Interface benannt benannt werden: /etc/wireguard/wg0.conf.
In diesem Beispiel lauscht der Wireguard-VPN-Server auf dem Port upd/443 auf eth0. Lediglich die Schlüssel müssen noch ergänzt werden:
[Interface]
Address = 172.16.100.1/24
Address = 2001:db8:ffff:ffff:100::1/72
SaveConfig = true
PostUp = iptables -A FORWARD -i %i -j ACCEPT; iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
PostDown = iptables -D FORWARD -i %i -j ACCEPT; iptables -t nat -D POSTROUTING -o eth0 -j MASQUERADE
ListenPort = 443
PrivateKey = [vpn-server.seckey]
[Peer]
PublicKey = [mobile.pubkey]
PresharedKey = [vpn.psk]
AllowedIPs = 172.16.100.0/24, 2001:db8:ffff:ffff:100::/72
Wireguard kann nun mittels wg-quick gestartet werden:
$ sudo wg-quick up /etc/wireguard/wg0.conf
Sollte der VPN-Server ohne Probleme starten, kann man die Konfiguration mittels Systemd persistent machen:
$ sudo systemctl enable wg-quick@wg0
DNS-Auflösung auf dem VPN-Server
Die Teilnehmer am VPN-Netzwerk sollen DNS-Anfragen durch den Tunnel an den VPN-Server richten können. In diesem Beispiel wird dnsmasq verwendet, aber auch andere resolver wie unbound können verwendet werden.
Eine exemplarische Konfiguration für dnsmasq (/etc/dnsmasq.conf):
# Quad9 - Initiative https://www.quad9.net/
server=9.9.9.9
server=149.112.112.112
server=2620:fe::fe
server=2620:fe::9
listen-address=127.0.0.1,172.16.100.1
bind-interfaces
cache-size=1000
Neustart von dnsmasq:
$ systemctl restart dnsmasq.service
Damit DNS-Anfragen an dnsmasq gerichtet werden, müssen auf dem VPN-Server die Nameserver in der Datei /etc/resolv.conf
auf eine Loopbackadresse verweisen. Dazu wird in der Datei /etc/dhclient/dhclient.conf folgende Zeile auskommentiert:
#prepend domain-name-servers 127.0.0.1;
prepend domain-name-servers 127.0.0.1;
Im Anschluss muss die Konfiguration neu eingelesen werden:
$ sudo systemctl restart networking.service
Wireguard-Konfiguration des Clients
Die Datei kann auf einem beliebigen System erstellt werden:
[Interface]
Address = 172.16.100.2/24, 2001:db8:ffff:ffff:100::2/72
PrivateKey = [mobile.seckey]
DNS = 172.16.100.1
[Peer]
PublicKey = [vpn-server.pubkey]
PresharedKey = [vpn.psk]
AllowedIPs = 0.0.0.0/0, ::/0
Endpoint = 203.0.113.1:443
Diese Datei kann nun als QR-Code kodiert werden und mithilfe der Android-/IOS-App eingelesen werden
$ qrencode -t ansiutf8 < client.conf
Das neue Zertifikat ist gültig bis zum 15.01.2020.
services:
- web
- jabber
- owncloud
fingerprints
SHA256:
51:49:8D:68:E8:2E:94:67:33:26:88:D5:14:85:16:60:65:D2:8E:F8:01:48:37:1D:1D:0C:87:6D:B6:89:84:87
SHA1:
DE:C8:CC:B4:2F:E7:6F:7C:92:1F:5B:B3:53:58:A8:C2:D0:83:03:5B
Das neue Zertifikat ist gültig bis zum 15.01.2019.
services:
- web
- jabber
- owncloud
fingerprints
SHA256:
18:44:C1:49:24:32:82:C5:DC:11:C8:23:6E:9C:42:6A:AE:AC:9E:C8:D6:60:B0:4C:CA:19:7D:05:6A:A5:41:03
SHA1:
5D:E1:83:5F:DD:C9:BF:E4:1E:5D:59:86:57:8E:6D:2D:64:DE:F1:4E
In Latex2e ist es möglich simple Programmierung durchzuführen, ohne das auf eine andere Programmiersprache zurück gegriffen werden muss. Nichtsdestotrotz unterstütz Latex natürlich eine Fülle an Programmierschnittstellen für alle gängigen Sprachen (z.B. Lua, Python, Perl, Bash …).
Das Grunddokument
Als Grunddokument dient folgender Aufbau, dass Paket ifthen stellt grundlegende Kontrollstrukturen, Vergleichsoperatoren und Schleifen zur Verfügung:
\documentclass[a4paper,10pt]{scrartcl}
\usepackage[utf8]{inputenc}
\usepackage{ifthen}
\begin{document}
...
\end{document}
Einfache Funktionen und Variablen
Man kann einfache Funktionen definieren, indem man neue Kommandos erzeugt. Im folgenden Beispiel wird ein Kommando mit zwei Pflichtargumenten erzeugt:
\newcommand{\distanz}[2]{Geben Sie die Distanz zwischen #1 und #2 an!\\\\}
Das Kommando kann auch noch nachträglich verändert werden:
\renewcommand{\distanz}[3]{Geben Sie die Distanz zwischen #1, #2 und #3 an!\\\\}
Eine einfache String-Variable wird ebenso angelegt und verändert:
\newcommand{\zielort}{Bonn}
\renewcommand{\zielort}{Berlin}
Die Funktion kann nun aufgerufen werden:
\distanz{Kiel}{Hannover}{\zielort}
Ausgabe
Geben Sie die Distanz zwischen Kiel, Hannover und Berlin an!
ganzzahlige Variablen
Ganzzahlvariablen (auch negativ) heißen in Latex counter und werden folgendermaßen deklariert und mit einem Wert versehen:
\newcounter{zaehler}
\setcounter{zaehler}{100}
Der Wert eines counters kann auch inkrementiert werden:
\stepcounter{zaehler} %zaehler++ -> 101
Das Addieren und Subtrahieren geht ebenso:
\addtocounter{zaehler}{10} %111
\addtocounter{zaehler}{-11} %100
Kontrollstrukturen und Schleifen
Jetzt kommt das Paket ifthen zum Tragen. Es bietet eine if-then-else-Anweisung und eine while-Schleife. Die Gesamtdokumentation dieses Paketes findet man hier.
Um lesend auf eine Variable/einen counter zuzugreifen, z.B. für einen Vergleich, dient folgende Anweisung:
\value{zaehler}
Möchte man stattdessen den aktuellen Wert als Dezimalzahl ausgeben:
\arabic{zaehler}
Um die Anwendung der Schleife und der if-Kontrollstruktur zu verdeutlichen dient folgendes Beispiel:
\newcounter{i}
\setcounter{i}{100}
\whiledo{\value{i} > 0}{
\noindent Wie viele Flaschen Bier sind noch da?\\
\addtocounter{i}{-1}
Es sind noch \textbf{\arabic{i}} Flaschen Bier im Kühlschrank.\\\\
\ifthenelse{\value{i} = 0}{\textbf{Es ist kein Bier mehr Da!}}
}
Ausgabe
Wie viele Flaschen Bier sind noch da?
Es sind noch 99 Flaschen Bier im Kühlschrank.
Wie viele Flaschen Bier sind noch da?
Es sind noch 98 Flaschen Bier im Kühlschrank.
...
Wie viele Flaschen Bier sind noch da?
Es sind noch 0 Flaschen Bier im Kühlschrank.
Es ist kein Bier mehr Da!